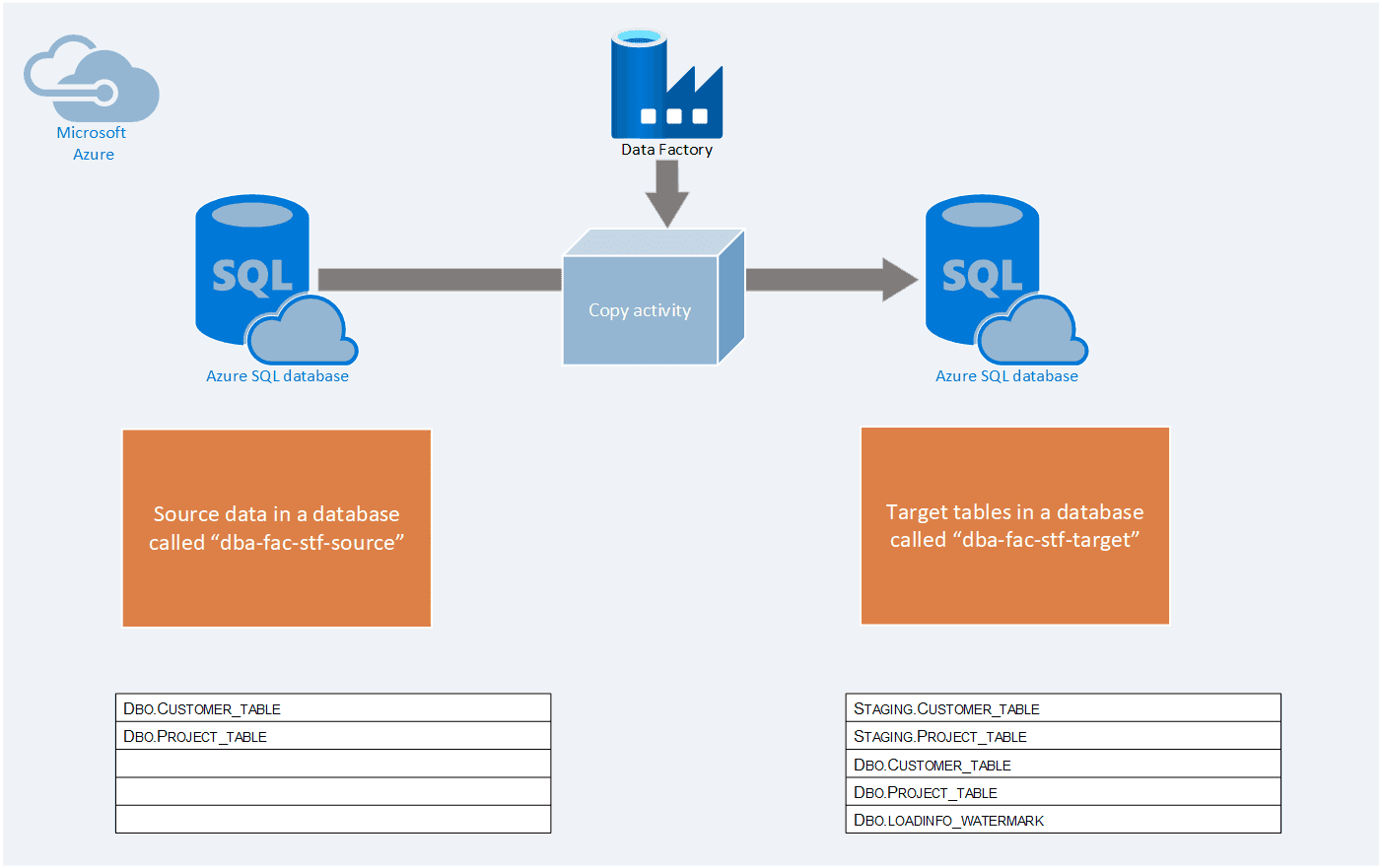
This is the very basic design
There are a few modern ways to do “change control”. This is when you control the change of your data on your destination (or target) tables. One of the latest is Azure Data Factories “Change Capture” feature, but it’s in preview as I write this, it’s a little buggy.
Let’s say that you have data in a SQL database that forms part of your source data that you want to extract and load into your live, operational tables that you use for reporting or whatever you may need it for. But you only want to load the data that is new, how do you go about that?
Somehow you will have to know what data has already been loaded in your destination table and compare with what is in the source data. Introducing the high watermark value, a default and very basic way to do incremental load AS LONG AS your source data table has a last modified date or some kind of date column that you can safely use to determine if that row of data is new.
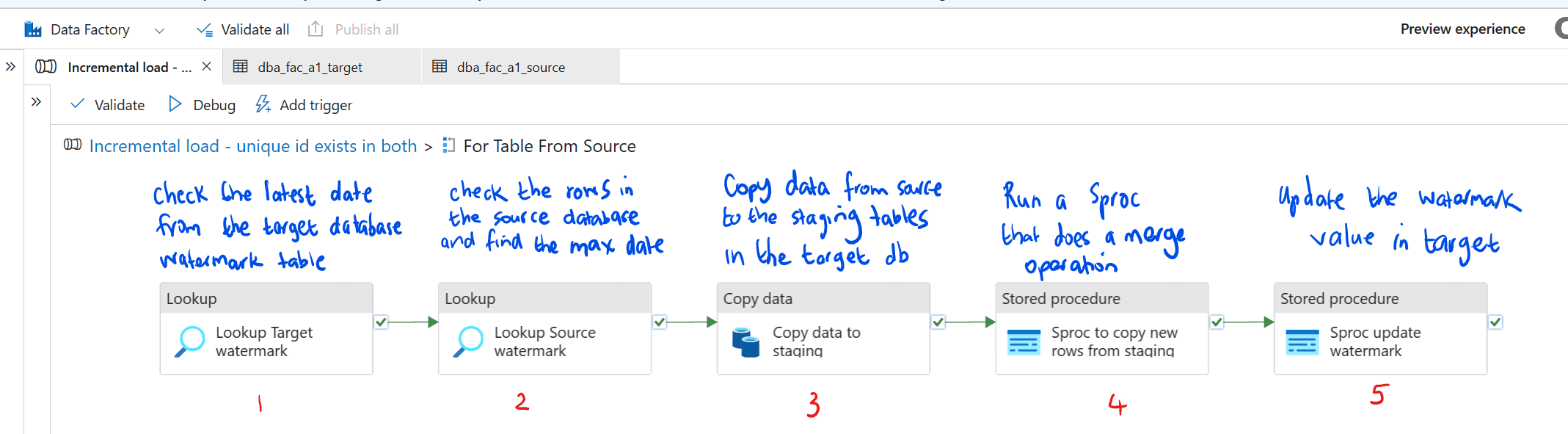
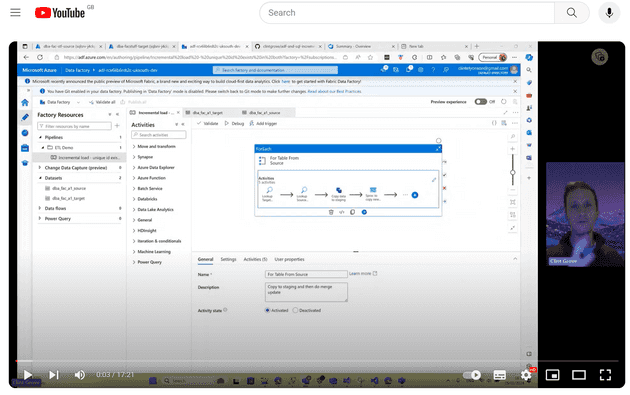
The Data Factory pipeline explained
- Lookup Target Watermark - Check the latest date from the target database watermark table, for the source table that you are trying to load
- Lookup Source watermark - Check the rows in the source database and find the max date
- Copy data to staging - Copy data from source to the staging tables in the target database
- Sproc to copy new rows from staging - Run a sproc that does a merge operation
- Sproc update watermark - Update the watermark value in the target database loadinfo_watermark table
Set up your own Azure Data Factory and SQL server
If you have an azure subscription you can spin this up, it’s really cheap, as I have made the databases the ones that cost ~£5 or so per month. And if you just deploy it and learn and then tear it down again it won’t cost you more than a few quid.
Follow my instructions on my github page to make the factory and sql server and then look at the ETL pipeline that I made just for this blog article.
https://github.com/clintgrove/adf-and-sql-incremental-load
The high watermark idea
Lets say you have a dataset on the source side that looks like this
| ModelName | lastModifiedDate | Cost |
|---|---|---|
| Gok y12 | 2022-01-10 | 32 |
| Zog x17 | 2023-04-05 | 211 |
| Yam t45 | 2022-11-09 | 74 |
In this example above, the row with the most recent date is the ModelName ‘Zog x17’ with a date of 2023-04-05. So if the table looked like this (see below) the next you do a extract and load, then the new rows to update would be
| ModelName | lastModifiedDate | Cost |
|---|---|---|
| Gok y12 | 2022-01-10 | 32 |
| Zog x17 | 2023-04-05 | 211 |
| Yam t45 | 2022-11-09 | 74 |
| Lul c56 | 2023-04-13 | 578 |
| Pol t95 | 2023-04-14 | 714 |
‘Lul c56’ AND ‘Pol t95’ which have dates after the 2023-04-05.
This all comes into play when you have the data pipeline that you will build (or is built for you in this github repo of mine)
What happens is that there is a look up to the “loadInfo_Watermark” SQL Table
The activity called “Lookup Target Watermark” does a SQL query and finds the latest date for the given table.
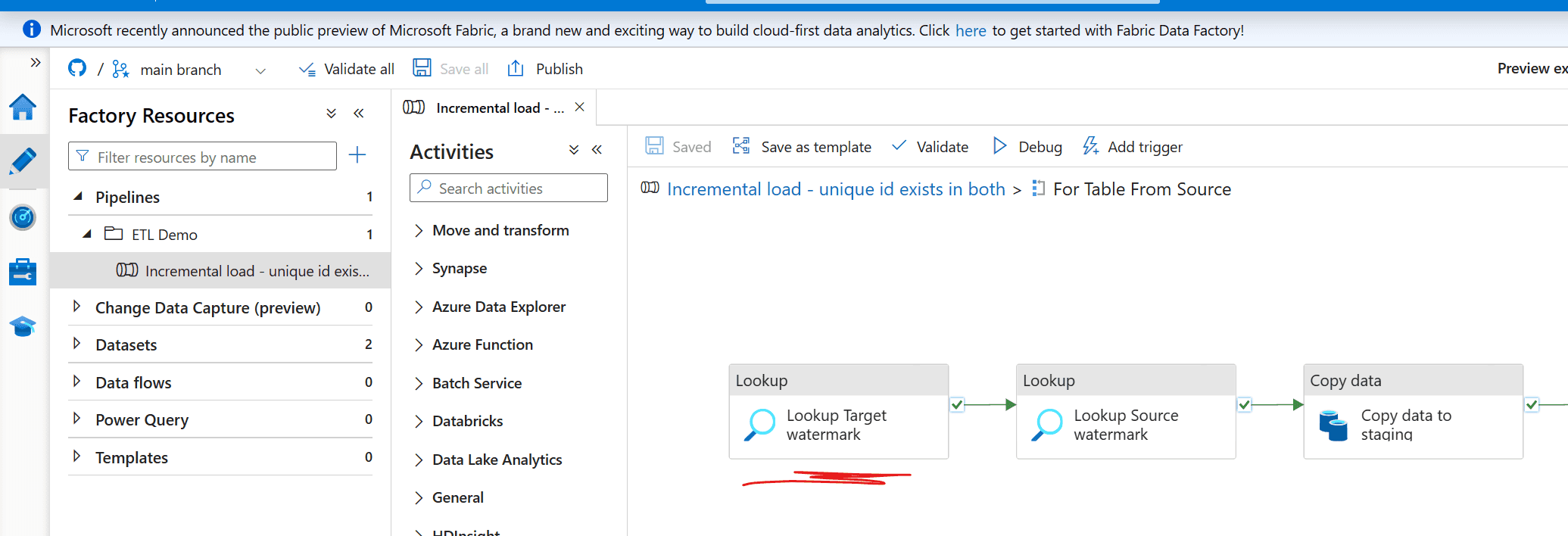
The very next activity is the “Lookup Source Watermark” which is looking at your source data and find the max date or lastModifiedDate
Source to Target loading
Without going too much into detail, as you can see the pipeline for yourself if you run the scripts I have made, but the next step is the copy activity.
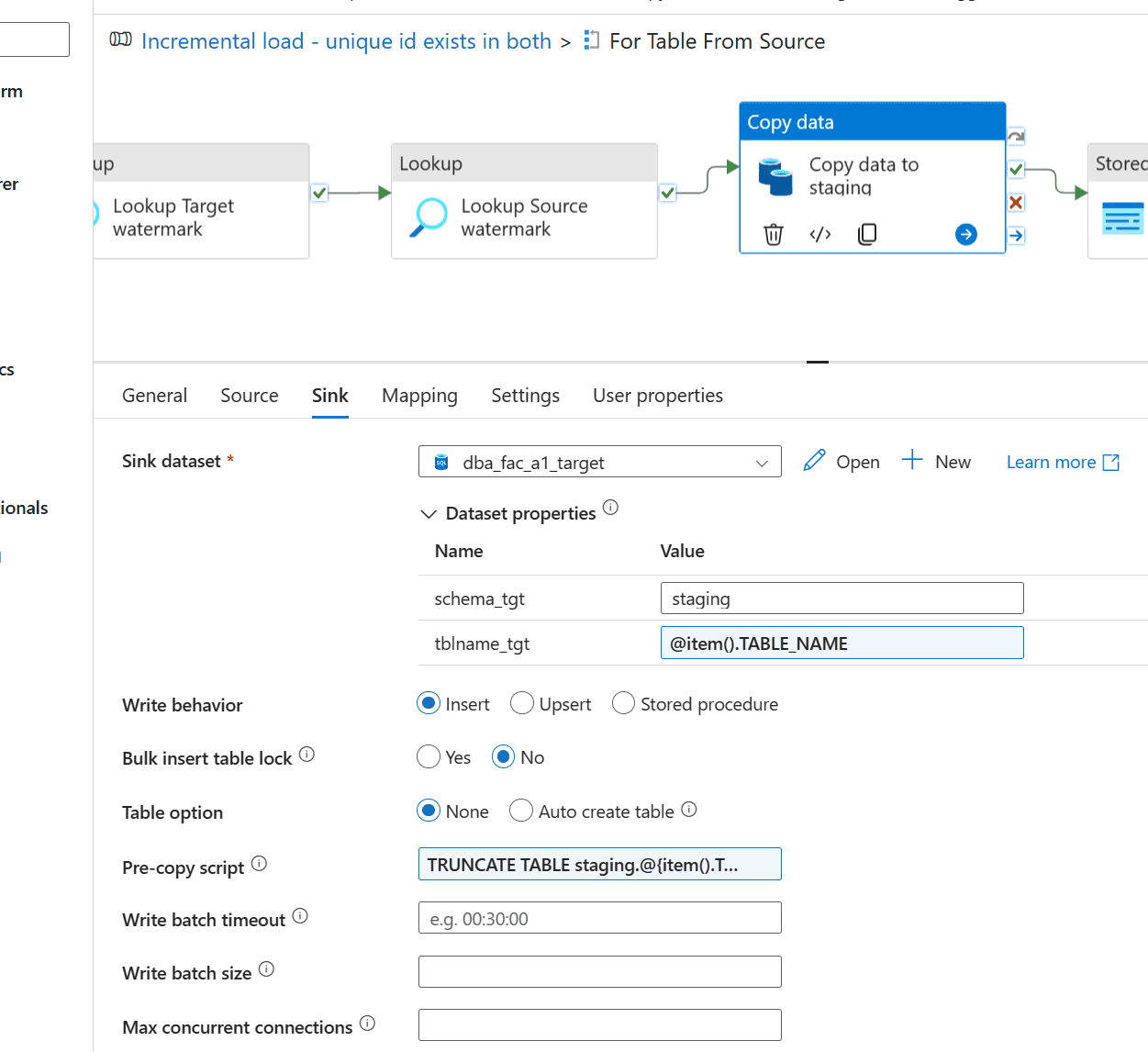
You copy data from the source (see the “Source” tab) and you sink it to the “staging” tables. See the name in the box for “schema_tgt”.
This is done so that you move the data from the staging table, which contains all the latest rows that have a date that is more recent than the date recorded on the loadinfo_Watermark table.
The query looks like this
select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('Lookup Target watermark').output.firstRow.dateofload}' and @{item().WaterMark_Column} <= '@{activity('Lookup Source watermark').output.firstRow.NewWatermarkvalue}'
Then a Stored Procedure executes a “Merge” statement like the one below
CREATE PROCEDURE [dbo].[usp_upsert_customer_table]
AS
BEGIN
IF OBJECT_ID('tempdb..#tempcustomer', 'U') IS NOT NULL
DROP TABLE #tempcustomer;
CREATE TABLE #tempcustomer (
PersonID INT,
[Name] VARCHAR(255),
LastModifytime datetime
);
INSERT INTO #tempcustomer
SELECT DISTINCT * FROM staging.customer_table;
MERGE customer_table AS target
USING #tempcustomer AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
ENDIn Closing
If you would rather watch a video of this, there is one here on my YouTube channel here
Thanks for reading. Reach out to me via the YouTube channel if you want help! https://www.youtube.com/@learndataengineeringwithclint